Photon Fault-tolerant and Scalable Joining of Continuous Data Streams
Abstract
在这篇论文中,我们会描述Photon的架构。Photon是一个可以实时高扩展低延时的,用于把多个连续数据流连接join的分布式系统。
Photon保证joined output在任何时间点(连接结果)没有重复(duplicate),这也叫最多处理一次语义(at-most-once semantics)。大部分可以join的事件(event)会以将近实时的速度出现在输出里(near-exact semantics),以及最终只处理一次(exactly-once semantics)。
简介
我们建造了一个叫做Photon的系统,可以把一个主要用户事件(primary user event),比如说是一个搜索请求, 和后续的事件(subsequent event),比如一个广告的点击,关联起来,在这些事件发生的几秒之内。
以一个点击和搜索事件的join为例:
- 用户发出一个搜索请求,谷歌服务器返回搜索结果以及对应的广告。这个服务器同时把这个事件发送到谷歌的多个日志数据中心。被日志记录的数据包括广告id,广告文本(ad text)等。这些数据之后会被用来生成报告,用来给广告主和质量分析。每个query event会被分配一个唯一id,叫做query_id。
- 收到搜索结果以后,用户可能会点击其中一个广告。点击事件同样也被记录和发送到多个日志数据中心。点击事件里面包含了用户点击的广告,可以被用于向广告主发送账单。而且点击事件也会包括对应搜索的query_id。同时每个点击事件会被分配一个唯一id,click_id。
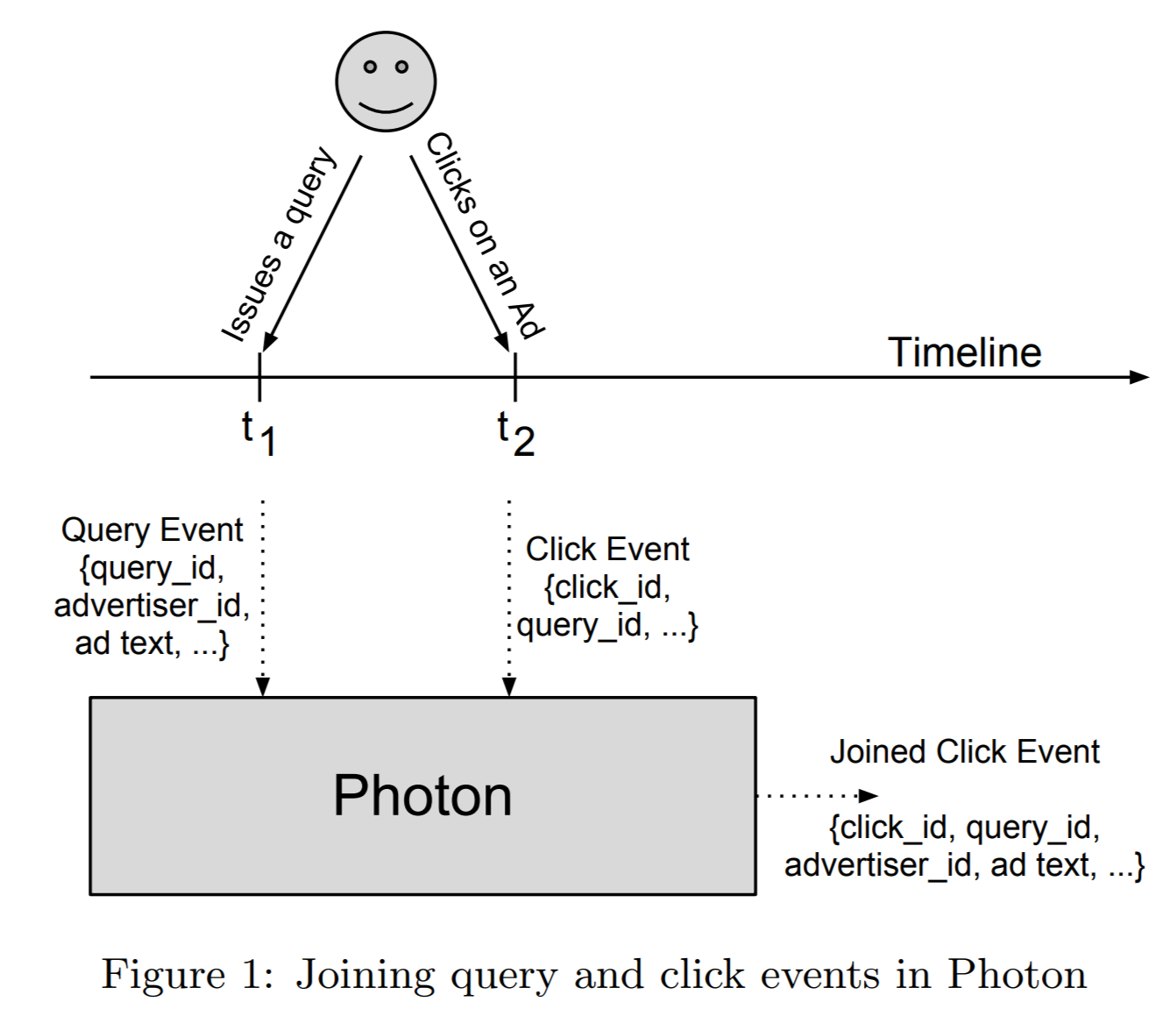
当我们生成最终统计数据的时候,我们需要得到整个事件的完整信息,包括搜索事件返回的所有广告,和点击事件。基于隐私,减少带宽消耗和提高用户体验等原因,我们不会把搜索的附加信息添加在点击事件里面。所以我们必须要做一次join才能把事件连接起来。
系统挑战System Challenges
- Exactly-once semantics只处理一次语义:因为被用于计费,所以必须保证事件不能被处理两次或以上,因为那会导致重复收费。但同时也不能丢失事件,因为那意味着谷歌会亏钱。
- 自动数据中心级别容错:数据中心会经常碰到事故,无论是计划还是计划外的。如果故障以后需要人工重设系统,那会十分不可靠。因为这个系统实在是太重要(计价),所以必须要做到数据中心级别的自动部署容错。保证即使是数据中心级别的故障灾难,也不会对系统的整体可用性造成影响,也不需要人工干预。
- 高扩展性
- 低延时:涉及到客户根据点击统计,实时调整广告计划
- 乱序流:主事件流(query搜索)基本上是根据时间排序的。但是外键流(foreign stream),比如说点击事件,则基本上不是根据query搜索的时间戳进行排序的。所以window join算法无法使用。
- 主事件流延迟(delayed primary stream):只有当对应主事件存在的时候,一个点击事件才能被join。但是因为分布式系统的原因,以及各种日志是独立被送到服务器的。所以query log相对click log迟到是很常见的事情。Photon必须有能力join日志,当日志准备好的时候。
基于paxos的id注册服务 Paxos-Based id registery
为了提供数据中心级别的容错,位于不同数据中心的Photon worker会尝试对同一个输入事件进行join连接。为了实现join最多一次的语义,worker必须协调他们的输出。